关于Codex中转站生图比例问题的解决记录
这篇文章记录一个最近折腾出来的小工具:relay-imagegen。
问题是怎么冒出来的
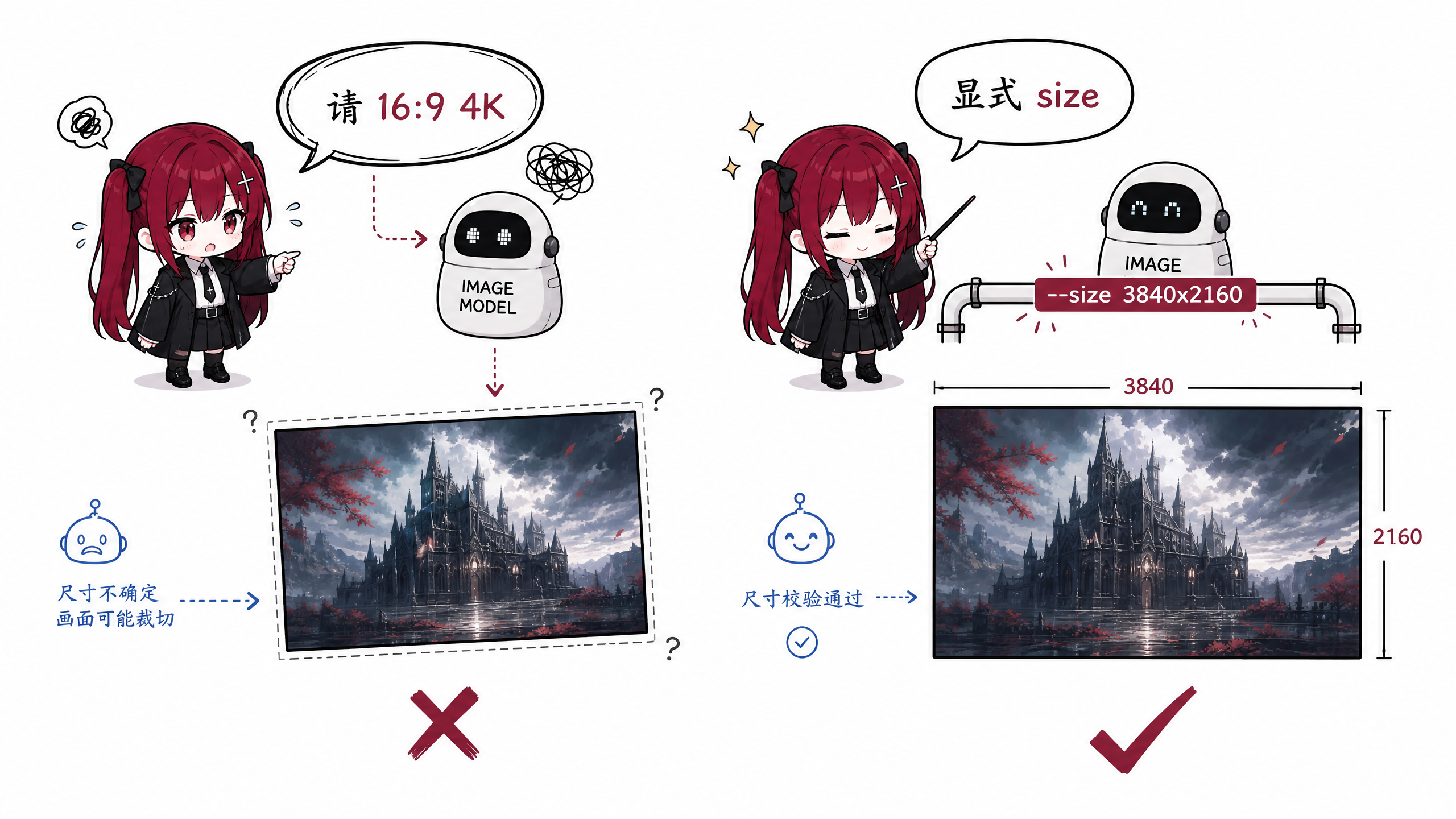
事情的起因很简单:我codex用的中转,同时我想让 Codex 帮我生图,而且希望它真的能按照我说的比例和分辨率出图。比如我说“16:9 横屏 4K”,它就应该老老实实传 3840x2160,而不是在 prompt 里写一句“please make it 16:9 and 4K”之后祈祷模型听话。
结果一开始当然是没那么听话。如下图:我让它出个4k的图

然后我到文件夹里面一看:1536x864算什么4k啊?

我:红温😡。
这个问题如果只是偶尔出一两张图,其实也无所谓。但是我自己用的时候,给我低分辨率也就算了,要求16:9给我个方图,那我就急了。
所以我需要的不是一个“更会画图的 prompt”,而是一个更像工程工具的,稳定的出图流程。
原始时代
在我开始思考做一个skill之前,是怎么出图的呢?
答案是给codex自己的key和中转的地址,让它自己用我的key和中转地址调用imagegen cli出图。
结果几乎每一次换对话都需要我单独给它强调一遍key和地址,太麻烦了。
于是就有了自动化的想法。
第一个想法:直接走中转站
我用 Codex 本身就是通过中转站,所以第一反应是:那图片生成是不是也可以直接走同一个中转站?
这里遇到的第一个小问题是 key。
正常 OpenAI SDK/CLI 喜欢读:
1 | |
但我不想把 OPENAI_API_KEY 写成系统环境变量。一方面不够干净,另一方面我本机还用了 ccswitch,这玩意在我本机系统变量写了key的时候会警告。我的目标是:key 只在本次出图进程里出现,跑完就结束,不进入系统环境,不进入命令行参数,不进入记录文件。
一开始的方案很朴素:把中转站配置写进一个 JSON 文件:
1 | |
然后写一个包装脚本,运行时读取这个 JSON,把 key 注入子进程环境,再调用 Codex 自带的 imagegen CLI。
也就是说,它不是一开始就自己实现图片 API,而是先做了一层包装:
1 | |
然后开始把流程做成 Skill
一开始只是一个脚本,但是每次都要和 Codex 解释“配置文件在哪、输出到哪、怎么传参考图、怎么传 4K”也很烦。
于是我干脆把它做成了一个 Codex Skill,叫:
1 | |
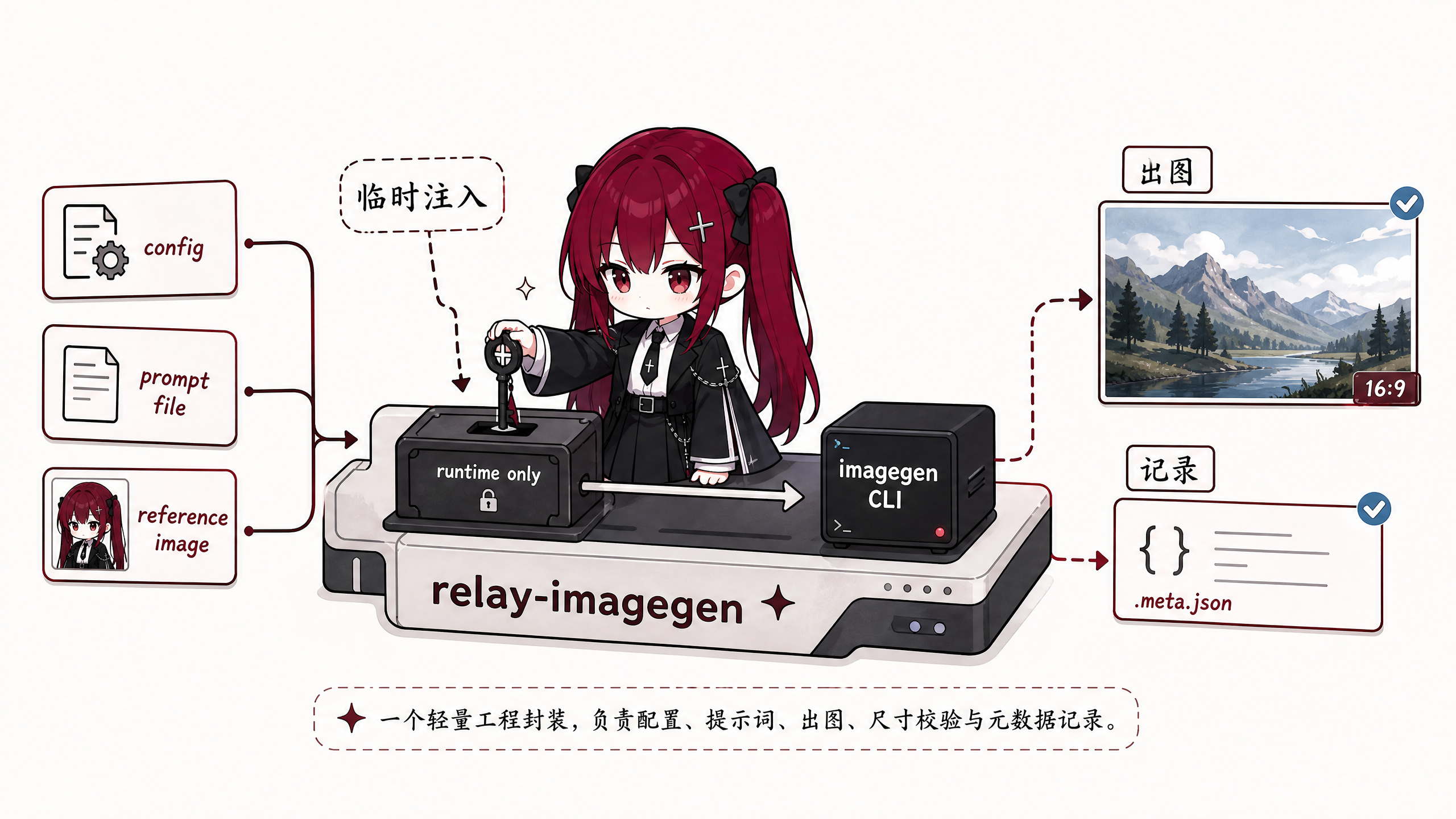
核心目标不是“这个 Skill 会画图”,因为原生 imagegen 本来就会画图。它真正解决的是周边流程:
- 读取中转站配置。
- 不把 key 写进系统环境变量。
- 明确传递
--size,让比例和分辨率稳定下来。 - 把 prompt 存成文件。
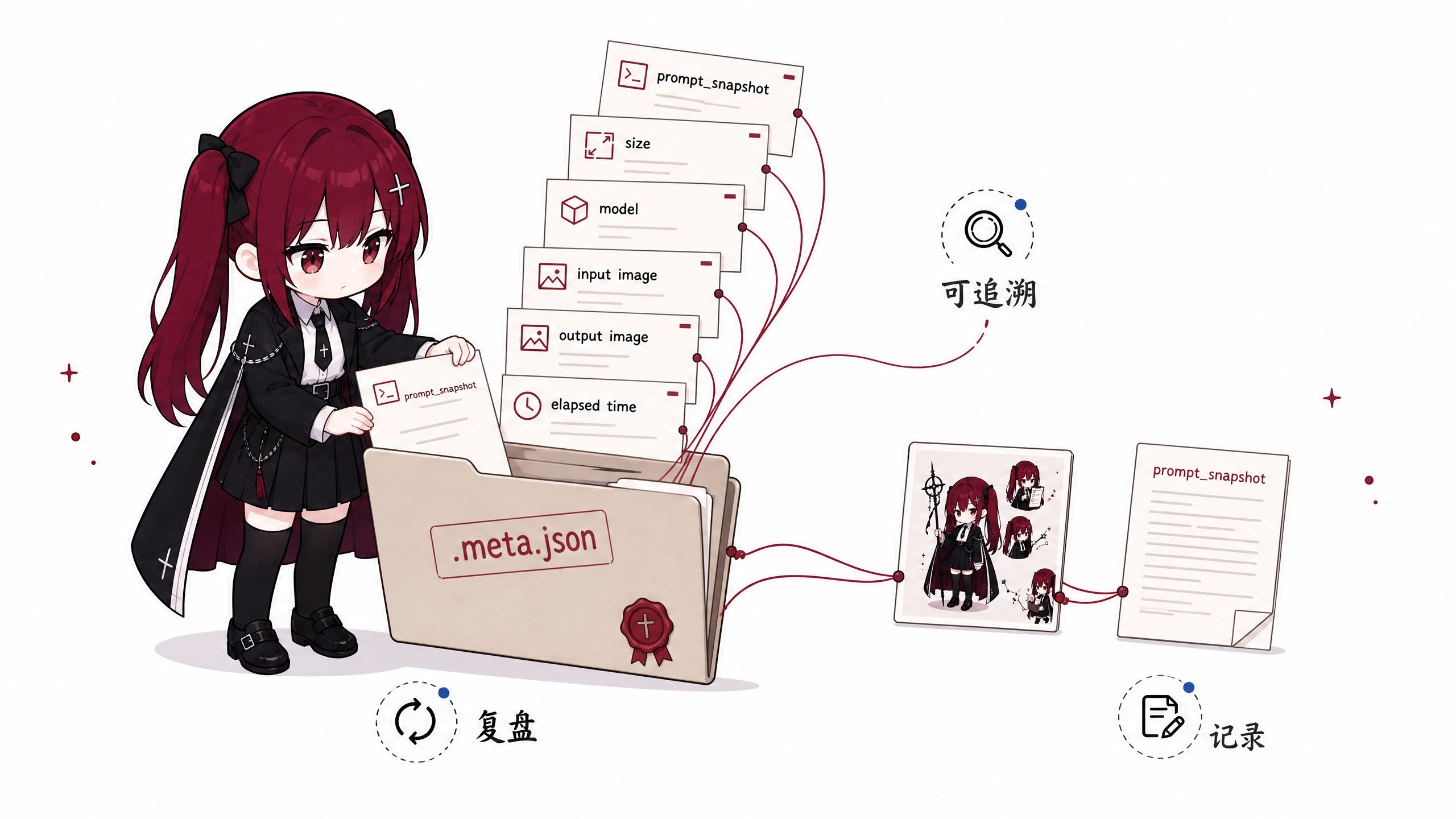
- 每次出图写一份
.meta.json。 - 记录 prompt snapshot、模型、尺寸、输入图、输出图、耗时。
- 参考图太大时先压缩再上传。
效果大概是这样:

这里面我比较满意的是,最后输出不是一句“图好了”,而是能明确知道:
1 | |
这就从“聊天里跑了一张图”变成了“本地有一次可追溯的出图记录”。
优化中转输入配置
一开始配置文件是手写 JSON。后来我发现这对别人来说还是有点麻烦,尤其是已经在用 Codex 中转站的人。
既然 Codex 本身已经能通过中转站工作,那为什么不直接读 Codex 当前配置呢?
现在这个 Skill 的默认读取顺序是:
1 | |
也就是说,如果你的 Codex 已经通过中转站跑起来了,那大概率不需要再配置任何 key。脚本会读:
1 | |
从 config.toml 里拿当前 provider 的 base_url,从 auth.json 里拿 OPENAI_API_KEY。当然,输出时只会显示脱敏 key,不会把明文 key 打出来。
ccswitch 这块也踩了一个很有意思的坑。
我做好了一个版本,自信满满的拿给我的小伙伴用,结果他那边出图卡了,找他拿到了对话记录后才发现,他那边读取的中转url不对😂,应该读到主站才对,居然读到hk开头的站了。于是开始查程序逻辑。
读取 ccswitch 的 endpoint 时,是从 provider_endpoints 表里拿最后一个 URL。结果最后一个 endpoint 是类似 hk.relay.example 这样的备用节点,但是这个节点是失败的,于是 Skill 就误读了一个不能用的地址。
所以就只能修改逻辑了:
- 优先读 ccswitch 当前 provider 配置文本里的
base_url。 - 只有没有
base_url时,才 fallback 到 endpoint 列表。
只能说在发现问题时,还是要快速定位问题发现的位置,在ai辅助下这个过程其实挺快的。
提示词记录其实很重要
做着做着,我发现这个工具最有用的地方不只是尺寸控制,还有提示词记录。
很多时候出图不是一次完成的,而是这样:
1 | |
如果这些 prompt 全都散在聊天里,等过几天再看,基本上就只剩“这图怎么来的来着?”。
所以现在的流程是使用:
1 | |
并且每次成功出图时,.meta.json 里会保存当次的 prompt_snapshot。这样即使之后 prompt 文件被改了,某一次出图实际用过的提示词也还在记录里。
这点对我来说非常关键。因为图片生成本身有随机性,如果连输入 prompt 都没保存,后面就完全没法知道图怎么来的了。
当然这也带来一个隐私问题:prompt 可能包含私密内容。所以后面如果继续完善,我可能会加:
1 | |
这样公开分享记录时可以选择只保存 hash,或者不保存完整 prompt。
这东西和原生 imagegen 差别在哪呢?
这个问题我自己也问过。
原生 imagegen 更像是:
1 | |
而 relay-imagegen 更像是:
1 | |
原生 imagegen 关心的是“能不能生成图”。relay-imagegen 关心的是:
1 | |
所以它不是要替代原生 imagegen,而是把我这种中转站用户常用的一整套流程封装起来。
如果你只用官方 OpenAI,而且只是偶尔让 Codex 出一张图,那原生能力够用了。
但如果你像我一样:
1 | |
那这个 Skill 就会顺手很多。
开源
既然做成了 Skill,我就顺手把它丢到了 GitHub:
https://github.com/AwakeFantasy/relay-imagegen
当然它现在还不是一个特别“稳固抽象”的项目。有人审查时就指出过,它目前还是包装 Codex 内置 imagegen CLI,而不是自己直接调用 Images API 或 Responses API。从长期维护角度看,这确实是一个耦合点。
我觉得理想的版本应该分成几层:
1 | |
甚至未来可以支持:
1 | |
但我现在觉得,先把真实工作流跑顺,比一开始就做一个大的重要。毕竟这个工具的诞生,本来就是因为我真的要用,真的被比例、分辨率、提示词记录这些问题折磨了。
最后总结一下
这次小工具给我的感受是:很多时候真正影响 AI 工作流体验的,不是模型本身能力不够,而是周边流程不够稳定。
你在对话里写了一大段 prompt,它可能留在聊天记录里,也可能过几天就找不到。但是如果你把它存成:
1 | |
再把当次 prompt snapshot 写进 .meta.json,它就变成了可追溯的资产。
总之,这次的结论是:
1 | |
祝读到这里的你也能少一点被默认参数折磨的时刻,多一点“我说 16:9,它就真的是 16:9”的快乐。(狗头)
本文配图使用 Avilia Blog Illustrations 流程生成。